Tolomisten heute

Ein kleiner Blick auf Google-Maps (.de/.at) genügt, um zu verstehen, wie das „Volk“ heute die Toponomastik löse, wenn sie nicht von Amtes wegen geregelt würde.

Ein User auf bbd, der auf den Umstand neulich hinwies und die Verdeutschung als lächerlich bezeichnete, wurde gleich mit Dislikes abgestraft.

Es ist auch nicht lächerlich. Es ist faschistisch.

Nun denn, können wir uns jetzt ja alle bei Google Maps anmelden und der Welt unsere persönliche Toponomastik aufzwingen. Das werde ich auch gleich tun, denn die Lafenn beispielsweise, die seit Menschengedenken so schön sprachneutral Lafenn heißt, müssen wir uns von keinen Experten zu Langfenn vergewaltigen lassen. Dann braucht es auch keine Lavena nicht.

Solltet ihr euch demnächst total verstört auf dem Salten verirren, weil euch Google Lafenn statt dem neudeutschen Langfenn und dem tolomeischen Lavena angezeigt hat, ich werde mir schelmisch-selbstgerecht den Bauch halten. Und was dabei lächerlich ist, entscheidet ihr.
Hi Benno,
Hi Benno,
durchaus interessanter Kommentar bzw. Gedankenanregung, die du da bringst. Die Grundlage von „Karl-Heinz“ hatte ich auch gelesen, aber eigentlich gleichc spektisch darüber, ob eure Vermutung (Datenmeldung/Korrekturmeldung bei Google) wirklich zutraf. Die vier Dislikes würde ich auch nicht überbewerten, du kennst Qualität der Dislike-Technik - und die Aussagekraft von vier Dislikes auf dieser Plattform ist wohl kaum Gesellschaftsspiegelnd.
Wo will ich hinaus? Wenn man das Marktpotential von big (spatial) Data verfolgt, darf man sich nicht wundern, was für Datenquellen alles angezapft werden, und wie hoch der Bedarf an möglichst viel Endonymen oder Exonymen ist.
(Wobei ich damit absolut weder Lust noch Intention habe zu belegen, dass deine Hypothese - jemand engagiere sich aktiv daran, veraltete Namen in einer Geodatenbank reinzuschwindeln - in diesem oder ähnlichen Fällen möglicherweise auch zutreffend sei, das kann tatsächlich immer sein).
Ein erster kleiner Cross-Check lohnt sich. Sporminore, ebenda in der Ecke, wird von Google Maps .de auf Neuspaur dargestellt, aber - hey - du kannst sogar bei Booking.com einen Agriturismo in Neuspaur finden! Faschisten auf booking.com? Eher nicht. Aber wo kommt dann dieses Datum her?
Schauen wir auf das Naheliegende: was meinte wikipedia (en) 2006 dazu? Dort kannte man ein „Sporminore“. Alles in Butter. Dann hat aber ein Herr Gryffindor sich die Mühe gemacht, die nach seinem Dafürhalten „ladinische“ Schreibweise „sporpiciol“ und die „deutsche“ Schreibweise „Neuspaur“ zu verewigen. Geschehen am 25.04.2011 (https://en.wikipedia.org/w/index.php?title=Sporminore&type=revision&dif…)
Ich kenne „Gryffindor“ nicht, aber ein kurzer Blick auf sein Profil birgt wunder: er/sie behauptet studiert zu sein und Faschismen zu verabscheuen (https://en.wikipedia.org/wiki/User:Gryffindor).
Er(oder sie) hat über 35.000 Änderungen an Wikipedia vorgenommen, ein paar Preise dafür eingeheimst, und scheint sich akademisch mit Sprachminderheiten auszukennen (https://en.wikipedia.org/wiki/File:Trentino-lingual_minorities.png). In Wikipedia Türkei ist er oder sie auch sehr aktiv, und andernorts auch. Kann das ein entfernter engagierter Experte sein, der sein Fachwissen zu Sprachminderheiten in Wikipedia verewigen wollte, und dabei nicht die Feinheit von „german (obsolete)“ vs. „german“ bei der Kennzeichnung nutzte?
Einmal ein solches Datum hineingebracht, passieren gar wunderliche Dinge: Die „deutsche“ Wikipedia Seite wurde erst 2012 automatisiert angelegt, so daß die von „Gryffindor“ hinzugefügte Deutsche Schreibweise „Neuspaur“ durch das automatische Anlegen sich dorthin hineinpflanzen durfte. Bis 2013 endlich ein User Mai-Sachme ein „deutsch (veraltet)“ daraus gemacht hat (https://de.wikipedia.org/w/index.php?title=Sporminore&type=revision&dif…)
So läufts in diesem Geschäft. Automatismen beschaffen sich Daten, wo sie nur können. Und versuchen diese zu aggregieren und die eigene Datenbank dann immer weiter zu vervollständigen. Über die Qualität der Datenquellen entscheiden keine Politiker oder Sprachwissenschaftler, sondern ganz pragmatische unternehmerische Entscheidungen. Vertrauen die Entscheidungsebenen bei einem Kartenhersteller der Schwarmintelligenz von Wikipedia, dann kann es sein, dass sie zu Nullkosten eine Unmenge an korrekten Exonymen automatisiert einlesen können. Dass dabei der eine oder andere Ausrutscher reinkommt, ist ein tolerierter Nebeneffekt. Der solange nicht auffällt, bis Gryffindor seine historisch-linguistische Studien in Wikipedia reinarbeitet.
Damit: eigentlich bin ich bei dir. Wer sich proaktiv mit den von dir unterstellten Motiven in einer solchen Modifikation von Toponymen engagiert, wäre zu bedauern, wenn er/sie das eben aus faschistischer oder revanchistischer Weltanschauung tun würde.
Aber - manchmal - gibt es viel harmlosere Gründe, wie ein Datum in Datenbanken landen kann. Ich wette, Gryffindor hat noch gar nicht kapiert, dass sein vielleicht ehrbarer Eingriff fünf Jahre später in Navigationssystemen landen würde, und ab dann Karl-Heinz und alle anderen Benutzer eines Deutschen User-Interfaces verwirren wird.
lg
Antwort auf Hi Benno, von Christoph Moar
Hoi Christoph, danke für den
Hoi Christoph, danke für den langen Kommentar. Interessante These, dass unser Schicksal unterentwickelten Algorithmen ausgeliefert wäre. Kein Zweifel, dass Google robots Wikipedia durchforsten, aber dass sie die Ortsnamen von dort ableiten würden, halte ich für etwas sehr konstruirt. Sappada/Plodn steht schon seit 2010 als „Bladen“ auf Wikipedia, Sauris als „Zahre“ seit 2004. Trotzdem werden sie von maps.google.de als Sappada und Sauris angezeigt.
2013 noch hatte ich Ferruccio Cumer darauf hingewiesen, dass Gummer auf maps.google.com nur als San Valentino in Campo dargestellt wird.
https://www.salto.bz/de/article/09072013/la-toponomastica-della-discord…
Mittlerweile - und natürlich dank der Mitgestaltungsmöglichkeiten von Google Maps - wird jetzt auch Gummer ZWEIsprachig(-namig) dargestellt. Eben diese Mitgestaltungsmöglichkeiten bieten der patriotischen Kampfszene ein willkommenes Spielzeug. Und natürlich streut man diese Seeds ganz bewusst, damit die Welt der Algorithmen gar wundersame Dinge daraus macht.
Antwort auf Hoi Christoph, danke für den von Benno Kusstatscher
Hm, weniger konstruiert als
Hm, weniger konstruiert als die Idee, Google Maps sei von Südtiroler Schützentruppen unterwandert worden? ;-) Man kann sich bei Google maps nicht einfach anmelden und dort Ortsnamen ändern. Man kann dort Vorschläge absondern, die dann mit einigem zeitlichen Abstand reviewt werden (von wem auch immer). Flächendeckenden Blödsinn kann man wohl nicht durchsetzen.
Also dass Google Maps seine „deutschen“ Ortsnamen im Trentino automatisiert von der englischsprachigen Wikipedia abgeerntet hat (konkret von hier: https://en.wikipedia.org/wiki/Municipalities_of_Trentino), halte ich für völlig evident. Google ist bei seinen zahlreichen Projekten recht bekannt dafür, sich nicht mit Detail- und Handarbeit aufzuhalten bzw. überhaupt inhaltliche Spezialisten zu beschäftigen, sondern sammelt seit jeher seine Daten „brachial“ automatisiert zusammen, mit allen nur denkbaren Fehlerquellen. Die vor Fehlern nur so strotzenden bibliographischen Angaben von Google Books sind beispielsweise ein beredtes Zeugnis dafür.
Aus meiner vagen Erinnerung: Ursprünglich kannte Google Maps in Südtirol überhaupt nur italienische Namen, das führte zu Protesten. Vermutung: Der Projektverantwortliche bei Google Maps scheint die Reklamationen dann im „Detail“ falsch verstanden zu haben (vielleicht wurde er auch von der englischen Wikipedia hinters Licht geführt) und hat deutsche Ortsnamen nicht bloß für die Provinz Bozen, sondern für die gesamte Region eingespielt. Sappada und Sauris sind deshalb nicht „deutsch“, weil außerhalb der Region. So langweilig, so unspektakulär.
Antwort auf Hm, weniger konstruiert als von Albert Hofer
ein bissi nachgeholfen wurde
ein bissi nachgeholfen wurde schon
http://www.brennerbasisdemokratie.eu/?p=8739
Antwort auf ein bissi nachgeholfen wurde von Harald Knoflach
jo, in dem Sinne macht es ja
jo, in dem Sinne macht es ja auch Sinn.
Antwort auf Hoi Christoph, danke für den von Benno Kusstatscher
Hoi Benno, danke fürs
Hoi Benno, danke fürs Feedback! Darf ich darauf eingehen?
Vorweg möchte ich sagen, dass ich keineswegs den konkreten Fall besprechen wollte, sondern übergreifend gezeigt habe, dass es „legitime“ Gründe gibt, dass jemand die alten Deutschen Namen dort im Trentino in einer Datenbank hinterlegt. Das ist die aus meiner Sicht wichtigere Aussage von meinem Beispiel - ohne den Wikipedianer Gryffindor zu kennen scheint mir sein Eintrag von damals aus ganz anderen Gründen zu entstammen als die von dir vermuteten faschistischen Tendenzen. Soweit, denke ich, sind wir uns vielleicht auch einig?
Dann ist mir wichtig dass du den zweiten Schritt siehst: wie ein Datum, dass irgendwo (aus annähernd legitimen Gründen) gelandet ist, durch Automatismen (im Beispiel eine automatisch generierte DE Instanz einer EN Seite) sich ein Fehler fortpflanzen kann. Kartographieanbieter jonglieren Daten aus unzähligen Quellen, augmentieren fehlende Informationen durch Dritt- und Viertdatenbanken und kaufen und verkaufen Datenbestände. Damit breitet sich ein Datenbestand potentiell nochmal weiter.
Zu deiner Vermutung „Kein Zweifel, dass Google robots Wikipedia durchforsten, aber dass sie die Ortsnamen von dort ableiten würden, halte ich für etwas sehr konstruiert.“
Natürlich kann es sein, dass die alten Deutschen Namen dort auch von einigen strammen Patrioten hinterlegt wurden - mein Beispiel wollte kein Gegenbeweis sein, sondern nur zeigen, dass es auch legitime Möglichkeiten geben kann.
Ohne also den konkreten Fall zu betrachten, sondern nur die Aussage „dass sie die Ortsnamen von dort ableiten würden, halte ich für etwas sehr konstruiert“:
Dass Google sich tatsächlich von Wikipedia und vieler anderer Quellen bedient, ist nicht konstruiert, sondern Fakt. Zunächst einmal beginnt die Geschichte bei Wikipedia selbst, die auf besagter Seite maschinenlesbare Metadaten hinterlegt, die unter anderem die Geokoordinaten und die Exonyme für bestimmte Sprachcodes beinhalten.
Beginne nun damit, „Neuspaur“ in ein beliebiges google (it, de) zu suchen, die rechts eingeblendete Box „Sporminore“ weist korrekt die Datenquelle Wikipedia aus. Dieselbe Suche in „Google Maps“ wird erneut den Ort darstellen, samt Datenquelle wikipedia. Das belegt natürlich noch nicht, dass der konkrete Wert der topografischen Entity „Neuspaur“ auch aus dem Wikipedia Eintrag entnommen wurde, sollte dir aber eine Einschätzung deines „...halte ich für sehr konstruiert...“ ermöglichen. Fakt ist: Google (Maps) bedient sich *auch* aus Wikipedia, so wie aus vielen Tausend anderer Quellen, und auch so, wie viele andere Dienste es auch tun.
Es gibt eine ganze Menge von technisch auswertbaren Datenbanken, die strukturierte Daten (im Unterschied zum Volltextindex von Google) liefern, und die von Google und allen anderen Marktbegleitern verwendet werden. Direkt oder indirekt verwursten diese Datenbanken *auch* Daten aus Wikipedia.
Der Reihe nach: da wäre zunächst einmal Freebase (https://developers.google.com/freebase/), das Vorgängerprojekt des Google Knowledge Graph Search. Freebase liefert strukturierte Daten, die auch von Kartenherstellern (Bing, Openstreetmap) ausgewertet werden. Freebase liefer ca. 2 Milliarden strukturierte Daten, unter anderem Personen und Orte, und teilt auch mit, dass es diese Daten aus Wikidata lernt.
Der „Knowledge Graph Search“ von Google, das Nachfolgeprojekt von Freebase, liefer zum Beispiel bei einer Suche nach „Sporminore“ (https://developers.google.com/knowledge-graph/how-tos/search-widget-exa…) die strukturieren Daten (ein „place“ Objekts) mit Hinweis der Datenquelle aus dem englischen Wikipedia-Content. Der strukturierte Record aus Wikipedia beinhaltet auch die Geokoordinaten, so dass eine hypothetische umgekehrte Suche (von Geokoordinate nach Place) vermutlich auch diesen Records zurückliefern wird.
Eine Suche in Google Trends ermöglicht dir auch, die Freebase Entities zu prüfen. Suche ich hier (https://www.google.com/trends) nach „Sporminore“ poppt die Entity „Neuspaur“ hoch, dessen Freebase ID
„%2Fm%2F0gb0r3“ ist (https://www.google.com/trends/explore?q=%2Fm%2F0gb0r3)
Aber noch leichter geht das, wenn du google selbst fragst, was Neuspaur ist. Sucher einfach „what ist neuspaur“ in ein beliebiges Google.
Die Suche hier (https://www.google.it/?gfe_rd=cr&ei=lbHyV_n4DKOT8Qezzo-AAg&gws_rd=ssl#q…) liefert dir die Antwort und auch die Information, woher Google das weiss - nämlich aus Wikipedia.
Weitere Quellen, die maschinell ausgewertet werden, sind Wikidata, dbpedia (http://live.dbpedia.org/page/Sporminore) und natürlich geonames.org (http://www.geonames.org/maps/google_46.237_11.03.html).
Wenn du bei letzterer auf die „7 items“ gehst und den Datensatz aus Wikipedia auswählst, dann auf die „alternate names“ klickst, findest du ein Dutzend andere Exonyme, vom Lateinischen bis zu etwas abwegigere Sprachen wie Armenisch oder Chinesisch. Aktuell weist auch geonames nicht oder nicht mehr die Deutsche Schreibweise aus, ich vermute, weil die Deutsche Wikipedia den Eintrag gestrichen hat, der Exonym „Neuspaur“ wird als „deutsch veraltet“ markiert und beinhaltet nicht mehr mit den lang-tag „de“ für Deutsch.
Ich hoffe, damit nicht Verwirrung zu stiften. Aber glaube mir, da Wikipedia Daten in hoher Qualität offen bereitstellt sind diese Daten danach nahezu überall sonst zu finden. Jede mir bekannte Datenbank, die mit strukturierten Daten arbeitet, zapft auch Wikipedia an, und die von mir oben genannten Kartendienste sowieso - man besorgt sich halt Daten, so gut es geht, und akzeptiert deren inhärente Fehlerquellen.
Offizielle Stellen (im Sinne von: staatliche Datenlieferanten) liefern halt nahezu ausschließlich Endonyme und kaum Exonyme in allen Sprachen der Welt. Dass die Crowd dann eine (geringe Anzahl) an Fehler findet und auch korrigiert ist mit einkaluliert, der umgekehrte Fall, dass eine Crowd bewusst Falschdaten injiziiert natürlich auch nicht auszuschließen.
lg
Antwort auf Hoi Benno, danke fürs von Christoph Moar
Christoph, abermals danke für
Christoph, abermals danke für den beeindruckenden Überblick. Wenn ich Dich richtig verstehe, stellst Du die These auf, dass sich Wikipedia ein lang-tag generiert, sobald jemand eintippt, Google das grabt und in seine Kartendaten einspeist, aber etwas nachlässig ist, die Daten zu relativieren, wenn der Wiki-Eintrag auf geändert wird. Da bleib ich skeptisch.
Die Variante, strikter strukturiertere Datenbanken (die vielleicht irgendwann mal von Wikipedia aus halbautomatisch gefüttert wurden) als Mittelsweg zu verdächtigen, klingt schon plausibler, zumal der sensibilisierte Umgang mit dem Wörtchen „veraltet“ nicht von jeder Datenbank zu erwarten ist. Also ein Gegenversuch:
Google Maps findet weder „Plodn“ noch „Ploden“, obwohl bei http://live.dbpedia.org/page/Sappada beide eingetragen sind, und findet bei „Bladen“ nur das gleichnamige Hotel, obwohl auf Wikipedia steht. Eine Suche auf Wikipedia selbst nach „Plodn“ führt zielstrebig nach „Sappada“. Genauso auf geonames.org. „Pladen“ findet Google Maps dann aber wieder, obwohl in keiner der besprochenen Datenbanken erstgenannt.
Deutet all das darauf hin, dass Google sich bei einer dieser Datenbanken (heute noch) bedienen würde, anstatt sich sein eigenes Kartenmaterial selbst zu verwalten und zu pflegen?
Antwort auf Christoph, abermals danke für von Benno Kusstatscher
Hi Benno!
Hi Benno!
1)
„Wenn ich Dich richtig verstehe, stellst Du die These auf, dass sich Wikipedia ein lang-tag generiert, sobald jemand eintippt...“.
Nein, Wikipedia generiert kein automatische Sprachmarkierung, wenn du „deutsch“ davorschreibst. Das macht nur ein Mensch. In meinem Beispiel (https://en.wikipedia.org/w/index.php?title=Sporminore&type=revision&dif…) ist vom Redakteur vor Neuspaur ein {lang-de} Tag vermerkt worden, der den maschinenlesbaren Hinweis gibt, dass dieser Begriff als *Übersetzung* der Ortschaft in der Sprache mit dem ISO-Code „de“ gedacht ist. Sowas geht auch noch präziser, du könntest auch mit regionalen Indikatoren wie {lang-de-CH} arbeiten. Ein automatischer Datenaggregator wird das Tag {lang-de} als eine maschinenlesbare Markierung eines alternate-Names verstehen, darum findet man auch solche „alternate Names“ in den strukturierten Metadaten, die sich aus Wikipedia speisen. Der „deutsch veraltet“ Begriff wurde hingegen nicht (mehr) als lang-tag gekennzeichnet, sondern als schlichten Text (Zitat: '‚Sporpiciol‘‚, deutsch veraltet: ‘‚Neuspaur‘') vermerkt, die Worte „deutsch veraltet“ bedeuten für Maschinen nichts mehr und wird damit in Datenbanken, die sich aus wikipedia:de speisen, nicht enthalten sein.
2)
„... aber etwas nachlässig ist, die Daten zu relativieren, wenn der Wiki-Eintrag auf geändert wird...“. Google oder der Datenlieferant macht ein Update nicht sofort, sobald das jemand eintippt: Die Generierung von Geodatenbanken ist teuer und aufwändig und erfolgt in Redaktionszyklen. Dabei werden dann tonnenweise Metadaten aus vielen Quellen aggregiert. So wie zum Beispiel „Sentres“ die Daten der Autonomen Provinz Bozen, von OpenStreetMap und vom Alpenverein einmalig zusammengewürfelt hat (und ab und zu den Prozess wiederholt), so nimmt Google Daten von Tausenden von Karten- und Datenlieferanten. Und selbst diese Lieferanten nehmen wiederum Daten von zig Quellen. Die Kernaufgabe der Kartenlieferanten sind dabei stets die Geodaten, die POI Markierungen werden dabei auch wiederum von zig Zulieferern aggregiert, bis hin zu den von Usern ausgefüllten Straßennummern aus den Captcha-Bildern.
3)
Wann welche Daten geupdated werden, ist damit nicht vorhersehbar. Fehler können damit auch lange Zeit drin bleiben, bis nicht jemand entscheidet, eine ganze Datenschicht durch ein Update von selber oder anderer Quelle zu erneuern oder zu ergänzen.
War die Quelle Wikipedia:en, und wird weiterhin diese Quelle verwendet, dann ist der „Fehler“ immer noch enthalten. Entscheidet der Datenlieferant, Wikipedia:en als Grunddaten zu verwenden, und darüber Wikipedia:de einzuspielen, dann wird der Fehler weiterhin bleiben, weil in der Wikipedia:de kein mit {lang-de} markierter Exonym existiert, der den anderen falschen überschreiben würde.
Oder jemand redaktionell eingreift, wie ich dir am Beispiel der „Deutschen“ Wikipedia Seite zeigen wollte. Es hat Jahre gedauert, bis der automatisch propagierte Fehler {lang:de}Neuspaur wieder manuell entfernt wurde.
OpenStreetMap, die auch ganz offen mitteilen, dass sie ihre Exonyme aus Wikipedia holen, haben offensichtlich eine bessere Vermischungsstrategie: http://nominatim.openstreetmap.org/details.php?place_id=158284262 vermerkt nur ein paar Sprachalternativen („ladinisch“ und „italienisch“, wenngleich in den verschiedenen Wikipedia-Seiten Dutzende von anderen Sprachen generiert und gekennzeichnet wurden), vermerkt wurde dann auch die quelle wikipedia:it (wikipedia calculated), vermutlich
4)
„...Deutet all das darauf hin, dass Google sich bei einer dieser Datenbanken (heute noch) bedienen würde, anstatt sich sein eigenes Kartenmaterial selbst zu verwalten und zu pflegen?...“
Google „harvested“ (~ ernten) Daten von unzähligen automatisierten Quellen und aggregiert diese. Die Geodatenlieferanten tun dassselbe. Dabei ist das kein global gültiger Prozess, es kann sein dass die Daten einer rumänischen Provinz von anderen Quellen befüllt werden als die vom Vatikanstaat. Von welcher Quelle oder Quellen die Exonyme zum POI Sporminore stammen, weiß ich wirklich nicht und wollte es auch nie behaupten - ich habe bereits bei meinem ersten Posting geschrieben dass ich das Beispiel nur als Beleg für den allgemeinen Fall betrachte, und nicht diesen spezifischen als bewiesen erachte.
Ich möchte mit meinen Rückmeldungen damit anmerken, dass es nicht ausdrücklich faschistische Absicht (der Tenor deines Kommentars) sein muss, wenn in einer Karte „falsche“ Exonyme stehen. Möglich, und dem Gesetz der Großen Zahlen folgend sogar wahrscheinlicher, sind auch Fehlerquellen durch fehlerbehaftete Quellen und automatisierte Prozesse, wie sie von den Datenlieferanten verwendet werden.
lg
Antwort auf Hi Benno! von Christoph Moar
Lieber Christoph. Das ist mal
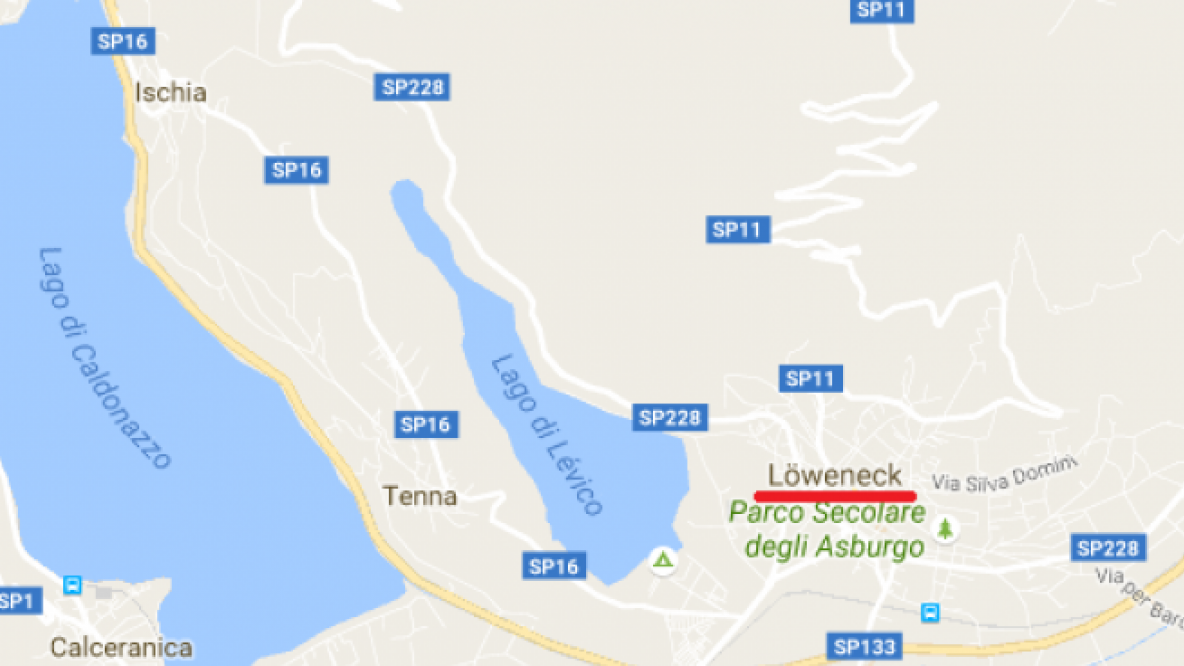
Lieber Christoph. Das ist mal Einsatz! Vielen Dank dafür! Punkt 1 macht so rum jetzt mehr Sinn. Für Punkt 2+3 denke ich, dass das Datenmaterial in Wikipedia und co schon über viel zu viele Jahre stabil ist, als dass es die Änderung in jüngerer Zeit bei Google Maps erklären könnte. Ich kann aber natürlich nicht ausschließen, dass ein jüngerer Strategiewechsel bei Google zu derartigen Artifakten führt. Ein Riva am Gardasee wäre dann aber immer noch viel wahrscheinlicher, als ein Reiff am Lago di Garda, womit wir bei Punkt 4 wären. Alles ist möglich und nix is fix. Dein Punkt ist verstanden. Deine Einschätzung von Wahrscheinlichkeit kann man, muss man aber nicht teilen. Wenn ich auf maps.google.it zur schweizer Grenze zoome, dann steht hierseits Italia und dort Schweiz. Nix Svizzera. Genauso Österreich statt dem vermuteten Austria. Auf .de und .com das Selbe. Also schaffen es die Google-Algorithmen nicht Gardasee und Italien einzudeutschen, aber Reiff, Arch und Löweneck sitzt. Zufälle gibt’s!
Antwort auf Lieber Christoph. Das ist mal von Benno Kusstatscher
Benno, alles was Christoph
Benno, alles was Christoph ausführt ist wesentlich wahrscheinlicher als die Story, die du hier rüberbringen willst, nämlich eine riesige Sprechpflegeaktion von Elmar-Thaler-Kumpels, die Google Maps übers Ohr gehaun haben...
Nochmals zum Thema, Punkte 2&3: Gab es denn eine „Änderung in jüngerer Zeit bei Google Maps“, die man erklären müsste? Die deutschen Ortsnamen im Trentino auf Google Maps kenn ich seit mindestens 2013... Die sind tatsächlich stabil. Ein lang-de-Tag steht seit exakt dem 25. April 2011 im englischen Artikel Spormaggiore (https://en.wikipedia.org/w/index.php?title=Spormaggiore&type=revision&d…) und steht immer noch unverändert dort rum.
Zu Punk 4: Zunächst mal muss man unterscheiden, in welcher Sprachversion man Google Maps betrachtet. Wenn ich jetzt gerade auf maps.google.it im Trentino rumschaue, entdecke ich keinen einzigen deutschen Ortsnamen. Wenn ich mir die den Deutschen oder Kanadiern angebotenen Versionen anschaue (maps.google.de und maps.google.ca) ist das Trentino plötzlich teutsch. Google arbeitet also sprachgruppen-sensitiv. Das deutsche „Schweiz“ auf maps.google.it kann ich übrigens nicht nachvollziehen, ich seh da ein Land namens „Svizzera“ mit Städten wie Berna, Zurigo, Lucerna... Dann zieht sich Google die Namen völlig verschiedener Objekte auch mit Sicherheit aus verschiedenen Datenbanken. Für die Staaten werden sie sicher andere Datenbanken verwenden wie für Gemeinden und wieder ganz andere für naturräumliche Objekte wie Seen oder Gebirge.
Grad dieses Assymetrie (nur Gemeinden sind eingedeutscht, Seen beispielsweise nicht) weist doch sehr entschieden darauf hin, dass hier nicht Welschtiroler Sprachpfleger unterwegs waren (die hätten nicht nur was gegen „Pergina Valsugana“ gehabt, sonder auch gleich noch den '‚Lago di Caldonazzo‘' daneben weggeräumt), sondern dass hier irgendwas automatisiertes passiert ist. In der Tat scheint dieses lang-de-Tag in der englischen Wikipedia flächendeckend nur bei den Gemeinden zu geben. Der „Lago di Caldonazzo“ (https://en.wikipedia.org/wiki/Lago_di_Caldonazzo) und der „Lake Garda“ (https://en.wikipedia.org/wiki/Lake_Garda) kennen hingegen keine deutschen Namen. Ich seh hier wirklich nichts Mysteriöses...
Antwort auf Benno, alles was Christoph von Albert Hofer
Albert, Du suggerierst jetzt
Albert, Du suggerierst jetzt schon zum zweiten Mal, ich hätte die Schützen gezielt im Visier. Nur fürs Protokoll, weder hatte ich das geschrieben, noch beabsichtigt. Warum das mit der Schweiz bei mir anders ist, keine Ahnung, aber danke für den Hinweis. Das mit 2013 bezeifle ich. Siehe meinen Salto-Beitrag „Alemagna Light“ vom September 2013, bei dem ein Google Maps Screenshot von einem „Mezzolombardo“ zeugt. Ich kann aber gefühlterweise bestätigen, dass sich die Dinger in etwa seit diesem Zeitraum langsam eingeschlichen haben.
Antwort auf Albert, Du suggerierst jetzt von Benno Kusstatscher
hier der Link
hier der Link
http://www.salto.bz/article/23092013/alemagna-light
Antwort auf hier der Link von Benno Kusstatscher
Ich entschuldige mich, dass
Ich entschuldige mich, dass ich dich falsch verstanden habe. Für mich klang das alles ohne Zweifel so, als verdächtigtest du hier politisch motivierte Personen am Werk, nämlich „Tolomisten“, die „der Welt [ihre] persönliche Toponomastik“ aufzwingen. Die Ausführungen von Christoph hast du zweifelnd kommentiert und die Zusammenfassung „Zufälle gibt’s!“ kann ich eigentlich nur so interpretieren, dass du immer noch nicht so recht an die unpolitische Version glauben möchtest.
Wie dem auch sei, ich hab kurz gegooglet: Jedenfalls hat schon im März 2014 eine gewisse Magda auf einer einschlägigen Website festgestellt: „ho visto con grande piacere che nella versione precedente di Google Maps, stanno comparendo anche i nomi originali delle ns. citta', dei toponimi (esonimi ed endonimi) Welsch Sudtirolesi di TN“ (http://www.welschtirol.eu/3-novembre-1918-loccupazione/). Das Auftauchen der deutschen Namen müsste also irgendwann zwischen September 2013 und März 2014 geschehen sein. Wobei man, wie gesagt, immer vorsichtig sein muss, welche SPrachversion man vor sich hat/hatte. Wenn ich mir jetzt grad aktuell in dem Moment google.it/maps mit meiner italienischen IP anschau, seh ich nicht mal in Südtirol einen deutschen Namen...
Antwort auf Ich entschuldige mich, dass von Albert Hofer
Nichts zu entschuldigen, Du
Nichts zu entschuldigen, Du hattest schon richtig verstanden: ich halte das alles nicht für Zufall und nicht rein für einen Google Unfall, nur wollte ich das nicht auf die Schützen runterbrechen wollen. Natürlich gibt mir Euer Einwand zu denken. Möglich, dass hier eins zum anderen kommt. Habe übrigens auf meiner Platte einen Screenshot von Sommer 2015 gefunden auf dem Löweneck noch Levico Terme hieß. Es täuscht mich also nicht, dass die Dinger sukzessiv kommen. Die Mechanismen verstehe ich nicht und den Verdacht muss ich unbelegt lassen.
hi benno,
hi benno,
dein eigener kommentar dazu hat 4 likes auf bbd. (http://www.brennerbasisdemokratie.eu/?p=31845#comment-311527)
wie sollen wir das jetzt interpretieren?
by the way. das mit den umbenennungen auf google maps ist lächerlich. ob es faschistisch ist, weiß ich nicht. genauso wenig wie ich weiß, wer dafür verantwortlich ist.
Antwort auf hi benno, von Harald Knoflach
Wie das zu interpretieren ist
Wie das zu interpretieren ist, weiß ich auch nicht, hunter. Wunderst Du Dich nicht auch manchmal über die Bewertungs-Dynamik?
Antwort auf Wie das zu interpretieren ist von Benno Kusstatscher
jeden tag. und deshalb nehme
jeden tag. und deshalb nehme ich sie auch nicht sehr ernst oder interpretiere gar etwas hinein.
Antwort auf jeden tag. und deshalb nehme von Harald Knoflach
interpretieren ist ein großes
interpretieren ist ein großes Wort. meinen Teil denken tue ich mir dann schon doch.
Sagen wir es so: Nicht
Sagen wir es so: Nicht wirklich viel Evidenz für einen Artikel.
Also diese deutschen Namen im
Also diese deutschen Namen im Trentino auf google sind mir auch schon in erstaunlicher Weise aufgefallen. Da ich aber eine Spaur als Urgoßmutter habe und es bekannt ist, dass die Familie Spaur sowohl in Welschtirol wie auch im deutschen Tirol beheimatet war, stets beide Sprachen zu ihrem Gebrauch hatte und auch in Österreich gar einige Ämter innehatte, ist die deutsche Bezeichnung von Unter- und Oberspaur durchaus zuzulassen. Sind wir im (gesamten!) alten Tirol nun zweisprachig oder nicht? :-)
Antwort auf Also diese deutschen Namen im von Sigmund Kripp
bzw. Alt- und Neuspaur, hatte
bzw. Alt- und Neuspaur, hatte ich vergessen einzufügen..
Dem Einwanderer Rampold kann
Dem Einwanderer Rampold kann man vieles vorhalten, aber nicht was Lafenn anbelangt. In seiner Landeskunde zu Bozen und Umgebung schreibt er konsequent Lafenn und man findet auch den folgenden Satz: „Derselbe Forscher (gemeint ist Hoeniger Anm) hat sich in dieser Arbeit sehr eingehend mit dem Namen der Örtlichkeit befasst, der heute (im Gegensatz zu früherem “Lavenn„ und “Langfenn„) allgemein richtig Lafénn geschrieben wird.“
Antwort auf Dem Einwanderer Rampold kann von Daniele Menestrina
Ouch, da hatte ich was im
Ouch, da hatte ich was im Gedächtnis genau verkehrtherum gespeichert. Vielen Dank für den Hinweis! Habe bereits den Text korrigiert, damit sich das bloß nicht vervielfältigt. Nochmals danke.
Benno, Liebe Gruesse aus
Benno, Liebe Gruesse aus Gallnoetsch :-) Anche se verrebbe più logico chiamarlo KaltundNass da questa stagione in poi...
Lavis mi risulta fosse Nevis auf Deutsch. Kronmetz, Reif, Trient ci possono stare. Così come Perzen, che in dialetto riprende il toponimo tedesco.
Altspaur e Neuspaur sono Spormaggiore e Sporminore, nominati secondo i vecchi Conti Spaur. Ma tipo che Schoeffbrueck sia Nave San Rocco, nemmeno dopo dieci bicchieri di teroldego...
Mi sono guardato la lista
Mi sono guardato la lista delle municipalità trentine in tedesco. Alcune le considero follie pure. Scopro ad esempio solo adesso di essere cresciuto a Zalban...Siccome Wikipedia è un’enciclopedia sarei curioso di capire da quali fonti provengono tali frutti della fantasia.
Antwort auf Mi sono guardato la lista von Mattia Frizzera
Ciao Mattia,
Ciao Mattia,
concordo, ma non me ne intendo.
Il nome „Zalban“ lo ha aggiunto l’utente Wikipedia „Gryffindor“.
https://en.wikipedia.org/w/index.php?title=Municipalities_of_Trentino&t…
in Data 00:09, 10 May 2011
correggendo una sua versione del giorno precedente, a quel dia ancora senza Zalban.
Come anche tutta la lista su wikipedia:en delle municipalità stessa é stata creata da Gryffindor in data 22:43, 25 April 2011
L’utente Gryffindor (https://en.wikipedia.org/wiki/User:Gryffindor), come scrivevo, sembra essere molto attivo su Wikipedia, ha scritto oltre 35.000 contributi, anche premiati, e sembra che se ne intenda delle minoranze etniche nel trentino, almeno ha redatto anche la seguente grafica con varie versioni. Ha due
https://en.wikipedia.org/wiki/File:Trentino-lingual_minorities.png
Se vuoi sapere la sua sorgente, basta scrivergli o aprire una discussion sulla pagina wikipedia e mettere in dubbio la sua scelta. A quel punto dovrebbe fornire prova.
Ciao